Family record book
Extraction and structuring of the useful civil-status information: identity of household members, family ties, dates and places of birth, and any details available depending on the pages analysed.
The trustworthy AI that makes your supporting documents reliable and speeds up the processing of your cases
ÉVIDENCE is a PI Project solution designed to automate the extraction, verification and structuring of the information contained in supporting documents.
Designed for the public sector, it turns heterogeneous documents (PDFs, scans, images, forms, certificates and more) into directly usable data, then acts on the case: chasing missing documents and forwarding data to business software.
Supporting documents are at the heart of many administrative processes: they provide proof, confirm a situation, secure a decision and feed business processes.
However, using them often remains manual, repetitive and costly. The useful information is scattered across varied, sometimes unstructured formats, which slows processing chains and heavily mobilizes teams.
ÉVIDENCE automates this key step: identifying the useful data, making it reliable, structuring it, then acting by chasing missing documents and feeding the processes concerned.
By way of illustration, here are three supporting documents frequently used in administrative procedures:
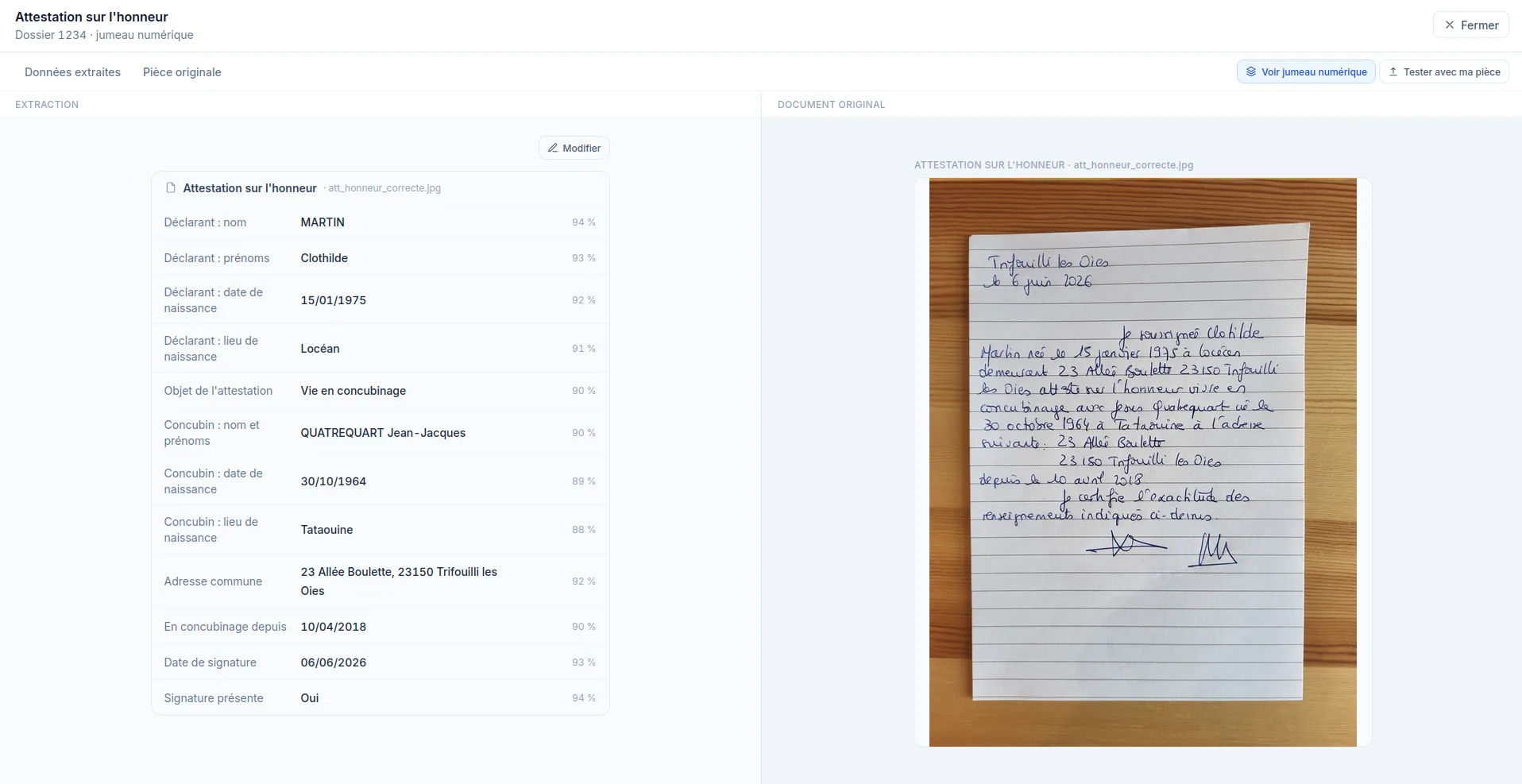
Extraction and structuring of the useful civil-status information: identity of household members, family ties, dates and places of birth, and any details available depending on the pages analysed.
Identification of the information relating to the declarant, the address, the date of the document and the elements that link a person to a place of residence.
Analysis of accommodation, cohabitation or common-law statements to identify the people concerned, the nature of the declaration, the declared address, the date and the meaningful elements of the document.
These three use cases illustrate ÉVIDENCE's ability to handle varied administrative documents, often semi-structured or unstructured, and to produce data that can be used directly in a business process.
The extraction detail shows each structured field next to the original handwritten document.
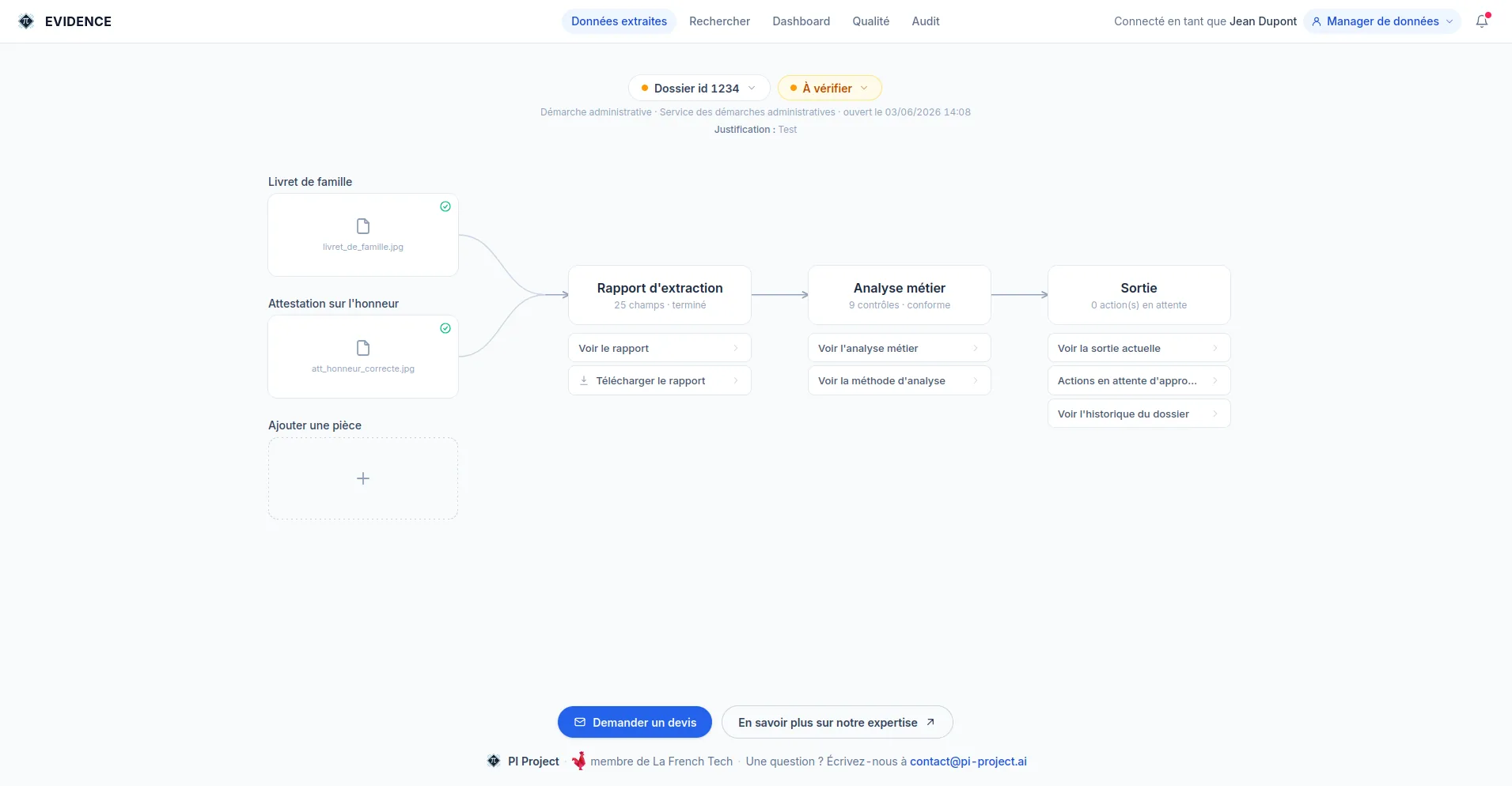
Incoming documents are sent to the solution through the channel agreed with the client.
ÉVIDENCE identifies the type of document, spots the useful information and extracts the relevant data.
The detected information is organized into a format that business processes can use.
The solution carries out the expected consistency, completeness and compliance controls.
The structured data is made available to feed existing workflows, applications or processing chains.
An automatic reading engine returns the content of a document. It does not tell you whether it read it correctly. Yet, in administrative processing, the risk does not come from the reading: it comes from the decision made on the basis of a wrong piece of data, without anyone noticing.
This requirement is not a refinement: it is inherent to the technology. New-generation reading engines (OCR, vision and language models) are probabilistic models: they estimate the most likely reading, they do not certify it. However capable it may be, such a model can, occasionally, be confidently wrong. The guarantee therefore cannot come from the model itself: it has to be built around it.
ÉVIDENCE is the layer that separates a piece of data that has merely been read from data you can act on. The value is not in extracting more: it is in guaranteeing what is extracted.
What makes the difference between a reading and a reliable piece of data:
When extraction fails or remains uncertain, ÉVIDENCE says so (failed reading, field to confirm) rather than presenting a guess as a fact. Whatever was not reliably read is flagged, never disguised as certain data.
The system recognizes when it is not sure and hands over to an officer at that precise moment: no decision is taken automatically on doubtful data.
Each piece of data stays attached to the original document. Any value can be inspected, verified and corrected next to the source document: nothing is produced without proof.
Every processing step is recorded: traceability is ensured end to end. A decision can be explained and reconstructed case by case, which guarantees auditability and remains enforceable in the event of a control or a dispute.
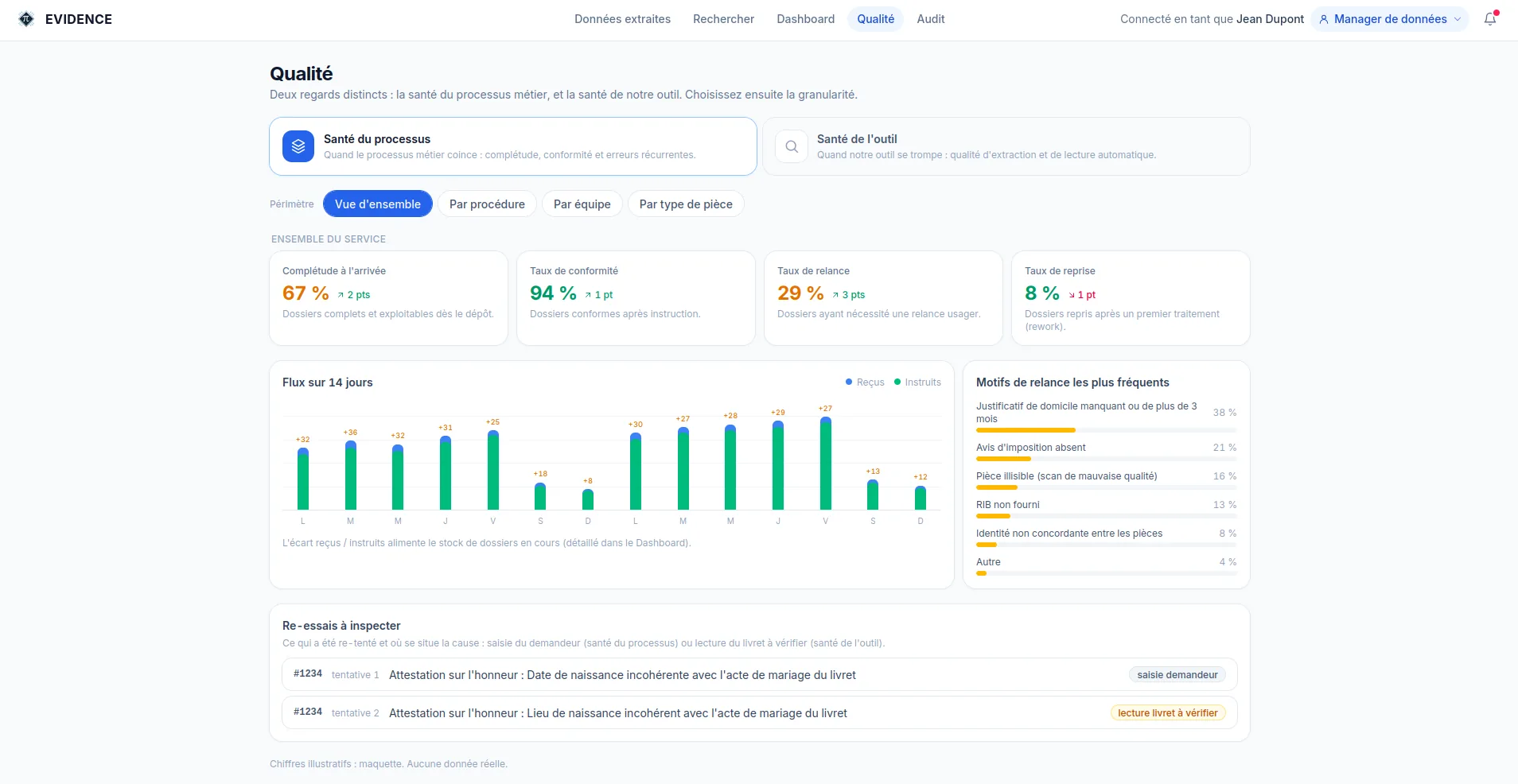
The reliability of an automatic process is not declared, it is measured. ÉVIDENCE continuously tracks the quality of the data produced, by type of document and over time, and flags any drift before it spreads.
To go further, the reliability achieved can be quantified: the level of reliability stops being an intuition and becomes a verifiable, documented and enforceable value.
Quality is tracked by type of document and over time. A drop in quality is detected, not endured.
A sized sample is re-processed by an independent human team, for a level of confidence defined in advance.
The results are quantified and documented. You do not take our word for it: you check.
This is also the whole point of an initial proof step: measuring the reliability of ÉVIDENCE on your own documents, with indicators you can control, before any large-scale deployment.
Behind these principles lie established methods, not assertions. Here, in plain terms, is what they make possible.
To guarantee reliability, there is no need to re-check every case. Statistics make it possible to calculate the exact number of cases to check to reach a given level of confidence. Counter-intuitive point: that number depends very little on the total volume.
A naive approach (“check 10%”) would impose 1,000 then 10,000 checks, for a guarantee that is itself never quantified. Sizing, on the other hand, fixes the guarantee first and derives the minimum effort from it.
Population processed
10,000
cases to check
567
Population processed
100,000
cases to check
597
Multiplying the volume by 10 barely increases the checking effort. 95% confidence, ± 4 points margin.
n ≈ z²·p(1-p) / E²
n: cases to check · z: level of confidence · p: expected rate · E: accepted margin. Corrected for a finite population.
We never give a figure on its own. A compliance rate always comes with the interval within which the real value lies. Without that margin, a percentage is only an assertion.
Quality is plotted on a control chart. A point that crosses the limits triggers an alert and an inspection, before the deviation spreads into the processes.
Flagged point: drift detected and put under review.
No single system is enough on its own. Potential deviations pass through several successive filters: at each stage, a share is stopped. What remains at the output is small, known and measured. It is this accumulation of controls, and not a single model, that produces reliability.
At the output, one last independent stage: the sized-sample control, which turns what remains into a quantified guarantee.
Methods used, each in its rightful place:
Several families of statistical methods work together, each in its rightful place: none is enough on its own, and it is their combination that makes the result solid.
A single overall figure is reassuring but does not guide. ÉVIDENCE tracks its indicators at several levels of granularity (by type of document, by step, by process, by period), to act precisely where the deviation is.
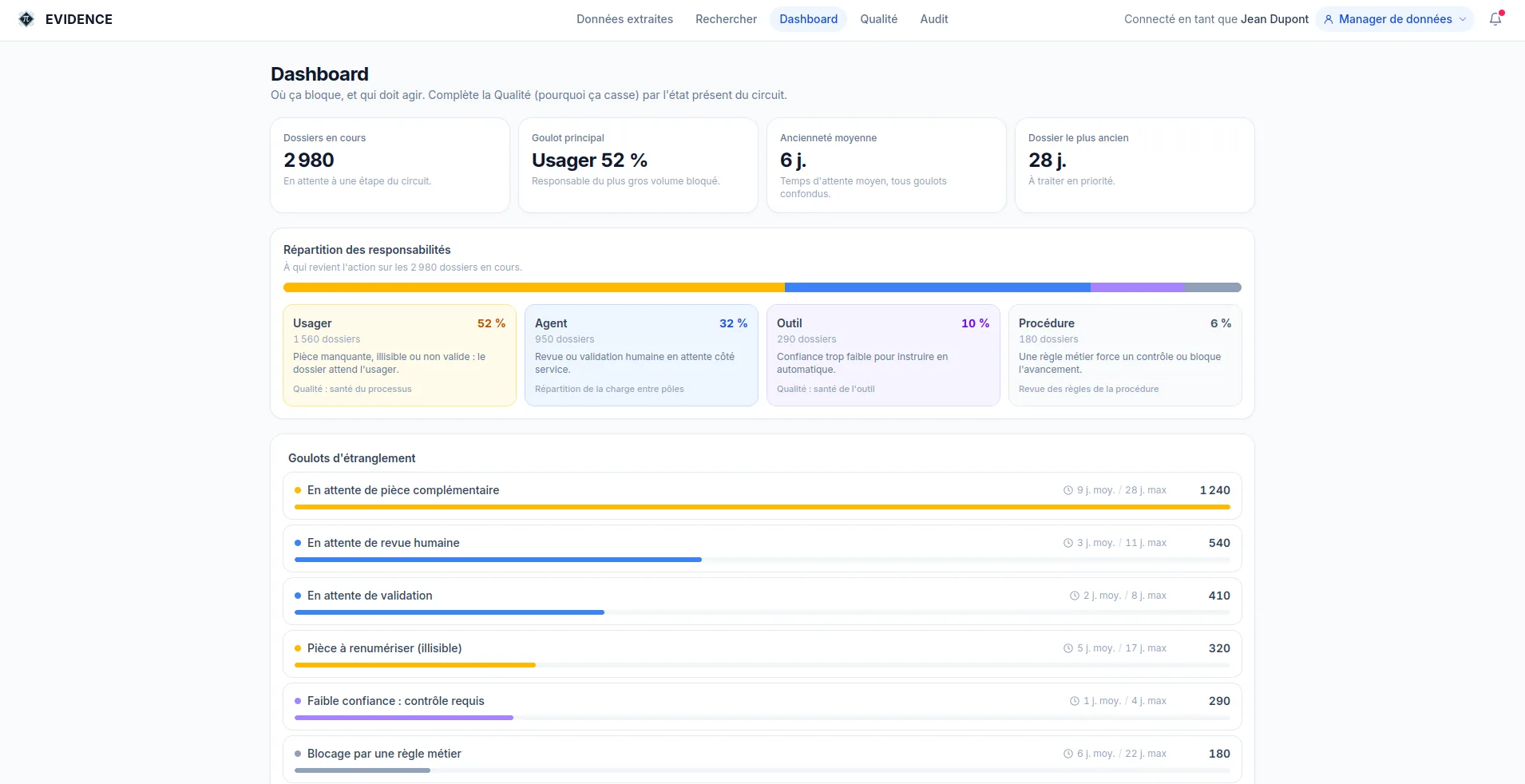
The share of cases processed correctly the first time, with no rework or correction. It is the indicator that links quality and cost.
Overall
94.2%
By type of document
The same indicator breaks down by process, by step and by period. Others follow the same logic: autonomy rate, final compliance rate, false-alert rate, for explicit control of false positives and false negatives, each with its margin.
Each deviation is linked to a cause. That way you treat the origin of the problem, not just its symptom, and you know what stems from the tool or from the process.
Breakdown of deviation causes
Distinguishing what comes from the tool from what comes from the process is decisive: the two are not corrected in the same place.
The performance of a process depends on two distinct things: the quality of the tool (reading, extraction, controls) and the quality of the business process (rules, documents requested, forms). ÉVIDENCE measures them separately.
So you know whether a deviation comes from the tool or from the process, and you can improve each one without disrupting the other. Two improvement loops, one shared measurement base.
Reading, extraction, automatic controls and decision thresholds. We improve it without touching the business side.
Business rules, documents requested, forms and decision circuits. We improve it without depending on a change of tool.
It is this decoupling that makes progress lasting: quality improves continuously on both sides, with no dependence on a single supplier or model.
ÉVIDENCE is often imagined as reserved for large organisations that already have an information system. That is indeed one of its uses: for these organisations, the solution integrates with existing applications and processing chains.
But ÉVIDENCE works just as well at small scale. A municipality, an institution or a department without a dedicated business tool can use it without deploying anything in-house, relying on an existing public service to collect supporting documents.
démarche.numerique.gouv.fr is a State service, operated by DINUM, that lets public officials create online forms. The principle is close to a consumer form: users submit their request and supporting documents in a dematerialized, structured way. This service acts as the entry point, and ÉVIDENCE takes over to turn the collected documents into usable data.
Online procedure
The user submits their supporting documents through a démarche.numerique.gouv.fr form, with no paper mailing or emails to sort.
ÉVIDENCE
ÉVIDENCE reads the documents received, verifies the useful information and turns it into reliable, structured data.
Officer or service
The officer gets clean, verified data to process the case, even without a business software in the local authority. ÉVIDENCE can also act: chase the user by email to obtain a corrected or additional document, or forward the extracted, structured data to a specialized software.
No development, no infrastructure to install: collection relies on an existing public service, and ÉVIDENCE processes the documents within a sovereign framework hosted in France.
Discover démarche.numerique.gouv.frÉVIDENCE provides a ready-to-use automation foundation, applicable well beyond the supporting documents presented above.
From this foundation, PI Project then designs a solution tailored to your environment: your documents, your business rules, your controls, your processing chains and your integration constraints.
The solution can be adapted to different contexts:
Processing of user cases
Checking of administrative documents
Verification of family or residence situations
Processing of documents related to accommodation or cohabitation
Structuring of incoming documents
Feeding business workflows or existing systems
Digital sovereignty is a decisive issue for public bodies, especially when the documents processed contain personal data.
With ÉVIDENCE, PI Project chooses concrete sovereignty: data is hosted in France, processed within a controlled European legal framework, and no supplier located outside the European Union is involved in the processing chain.
What this means in practice:
Data hosted in France
Processing chain with no supplier located outside the European Union
Model-agnostic approach
No dependence on a single supplier
Adaptation to each organisation's constraints
Client control over purposes, uses and data
ÉVIDENCE is also designed with technological independence in mind. PI Project does not depend on a single supplier, an imposed technology or a specific proprietary model. This approach limits the risks of technological lock-in and makes it possible to adapt the solution to each organisation's requirements.
PI Project acts as a GDPR processor: the client keeps control over its data, its purposes and its uses.
The economic performance of a document process often hinges on tasks that are barely visible but heavily resource-consuming: reading documents, searching for useful information, matching, checking or routing cases.
By automating the extraction and structuring of the data contained in supporting documents, ÉVIDENCE reduces the time spent on these repetitive but essential operations.
The solution thus helps to control the unit cost of processed cases, to absorb activity peaks more efficiently and to reserve human intervention for specific checks, arbitration and situations that truly require business expertise.
ÉVIDENCE is aimed at public administrations, local authorities, hospitals and, more broadly, any public operator that wants to industrialize the processing of its supporting documents without losing control over its data, its processing and its technological dependencies.
The solution is part of a logic of rigour, transparency, traceability, compliance and trust.
Public administrations
Public institutions
Local authorities
Hospitals
Public operators
ÉVIDENCE is a sovereign solution, hosted in France and designed for the public sector. On that basis, local authorities may, depending on their eligibility, draw on dedicated support schemes for adopting a sovereign AI.
Banque des Territoires (Caisse des Dépôts group) has launched the Territoires d'IA programme, which notably provides a co-funding scheme to make it easier for local authorities to acquire sovereign AI solutions.
The eligibility conditions, the amount and the nature of the funding are a matter for Banque des Territoires and are assessed case by case. PI Project is not involved in processing these applications.
Discover the Territoires d'IA programmeTalk with PI Project
Show us your documents and your use cases: we study their automation with ÉVIDENCE and send you a tailored proposal.