PartRef Rodeo
Operator access to fragmented catalogues, across several generations of the product
R2C has a historical documentation covering several Rodéo variants. The documents exist, but as scans: they are not directly searchable and do not allow simple text search.
The difficulty is not limited to this lack of full-text search. Within a single document, several forms of reference can coexist; some parts appear in multiple variants, sometimes in several places, with naming conventions that can vary by generation, by section, or by technical context. Under these conditions, using the documentation becomes difficult as soon as the user only has a part, a partial reference, or an isolated clue: one has to know where to look, in which variant, in what form the part might be designated, and how to interpret the different occurrences found.
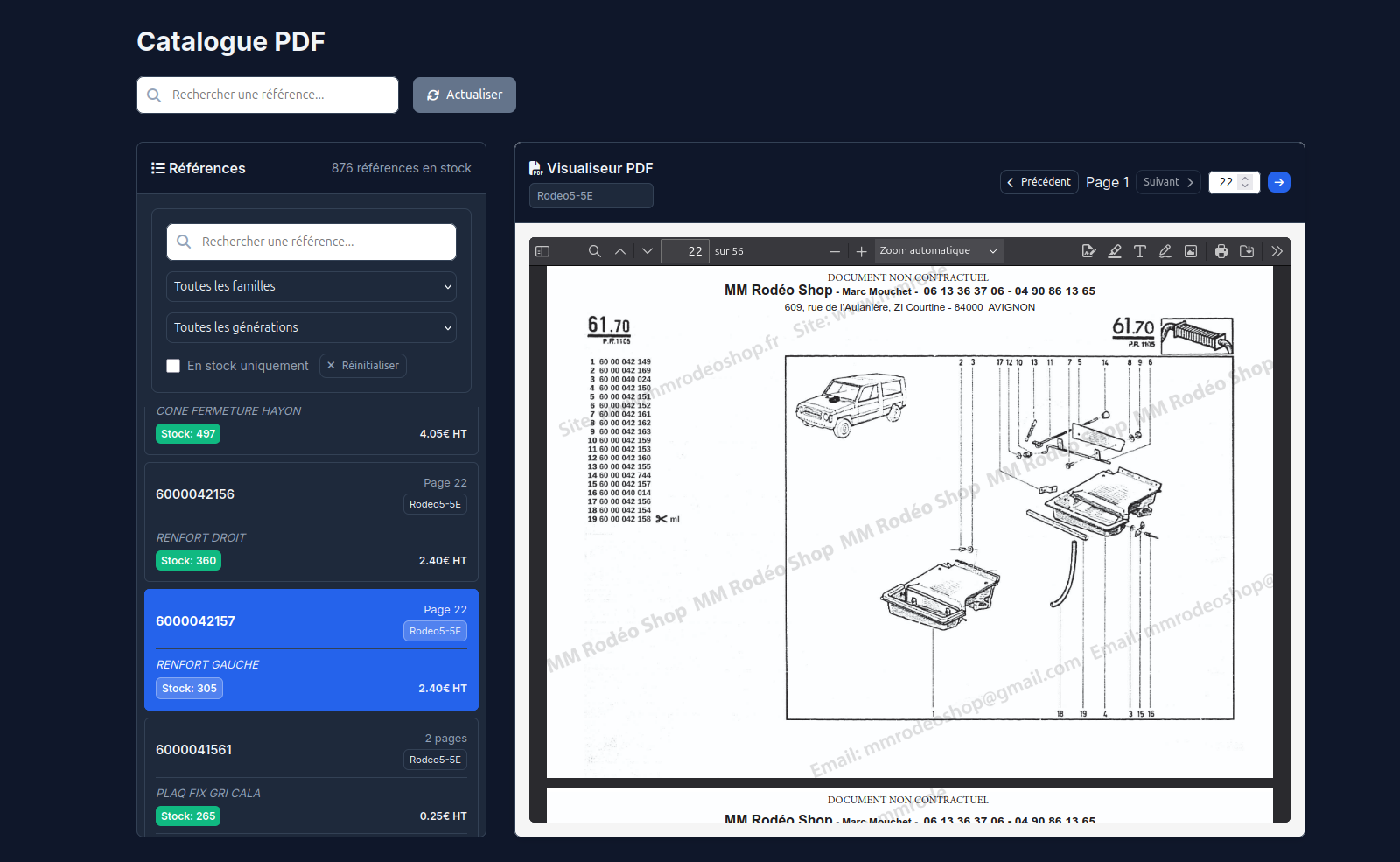
PartRef Rodeo turns this historical documentation into a usable access point. The system makes the scans searchable, organises results by document, page, and variant, then returns each occurrence in its visual context. It is therefore not just about extracting text, but about preserving the link between each piece of information and its source: document, variant, page, visual zone, and documentary environment.
This traceability allows the combination of exact search, fuzzy search, and operator verification, without producing a mere list of ambiguous matches. The documentation remains the central source of truth: the solution simply changes how it is accessed, by displaying the relevant page directly so the user can verify, contextualise, and resolve any doubts.
Cross-referencing with business data
Once the references are extracted and contextualised, PartRef Rodeo is not limited to documentary navigation. The identified occurrences can be cross-referenced with the client's stock data: references present in stock, declared units, balances, code formats, orphaned parts, or inconsistencies between catalogue and operational data.
This cross-referencing surfaces anomalies that would remain hard to detect in a conventional documentary read: inconsistent units, negative balances, malformed references, parts present in stock but hard to tie to a documentation, or documented references missing from the operational data.
The value of the system therefore does not lie solely in searching the scanned catalogues. It lies in the link established between documentary heritage and the business repository: the documentation becomes a tool for control, reconciliation, and audit.
Operational effect
The user can find a part or a reference without knowing in advance the right catalogue, the right page, or the right naming convention. The tool thus reduces the cost of using old, fragmented documentation, while exposing inconsistencies in the associated operational data.
It does not replace business knowledge: it makes it more effective. It prevents operator expertise from being consumed by long, ambiguous searches dependent on individual memory, and focuses human intervention on the cases where a decision or a correction is actually needed.
- Scanned document ingestion
- Extraction of non-searchable content
- Indexing by document, page, and variant
- Handling multiple reference patterns
- Exact and fuzzy search
- Cross-referencing with stock data
- Business anomaly detection
- Operator access to the documentary source