Livret de famille
Extraction et structuration des informations d'état civil utiles : identité des membres du foyer, liens familiaux, dates et lieux de naissance, mentions disponibles selon les pages analysées.
L'IA de confiance qui fiabilise vos pièces justificatives et accélère l'instruction de vos dossiers
ÉVIDENCE est une solution de PI Project conçue pour automatiser l'extraction, la vérification et la structuration des informations contenues dans les pièces justificatives.
Pensée pour la sphère publique, elle transforme des documents hétérogènes (PDF, scans, images, formulaires, attestations...) en données directement exploitables, puis agit sur le dossier : relance des pièces manquantes et transmission aux logiciels métier.
Les pièces justificatives sont au cœur de nombreux traitements administratifs : elles apportent la preuve, confirment une situation, sécurisent une décision et alimentent les processus métiers.
Cependant, leur exploitation reste souvent manuelle, répétitive et coûteuse. Les informations utiles sont dispersées dans des formats variés, parfois non structurés, ce qui ralentit les chaînes de traitement et mobilise fortement les équipes.
ÉVIDENCE automatise cette étape clé : identifier les données utiles, les fiabiliser, les structurer, puis agir en relançant les pièces manquantes et en alimentant les traitements concernés.
À titre d'illustration, voici trois pièces justificatives fréquemment mobilisées dans les démarches administratives :
Extraction et structuration des informations d'état civil utiles : identité des membres du foyer, liens familiaux, dates et lieux de naissance, mentions disponibles selon les pages analysées.
Identification des informations relatives au déclarant, à l'adresse, à la date du justificatif et aux éléments permettant de rattacher une personne à un lieu de résidence.
Analyse d'attestations d'hébergement, de vie commune ou de concubinage afin d'identifier les personnes concernées, la nature de la déclaration, l'adresse déclarée, la date et les éléments signifiants du document.
Ces trois cas d'usage illustrent la capacité d'ÉVIDENCE à traiter des documents administratifs variés, souvent semi-structurés ou non structurés, et à produire des données directement mobilisables dans un processus métier.
Le détail d'extraction affiche chaque champ structuré en regard du document manuscrit d'origine.
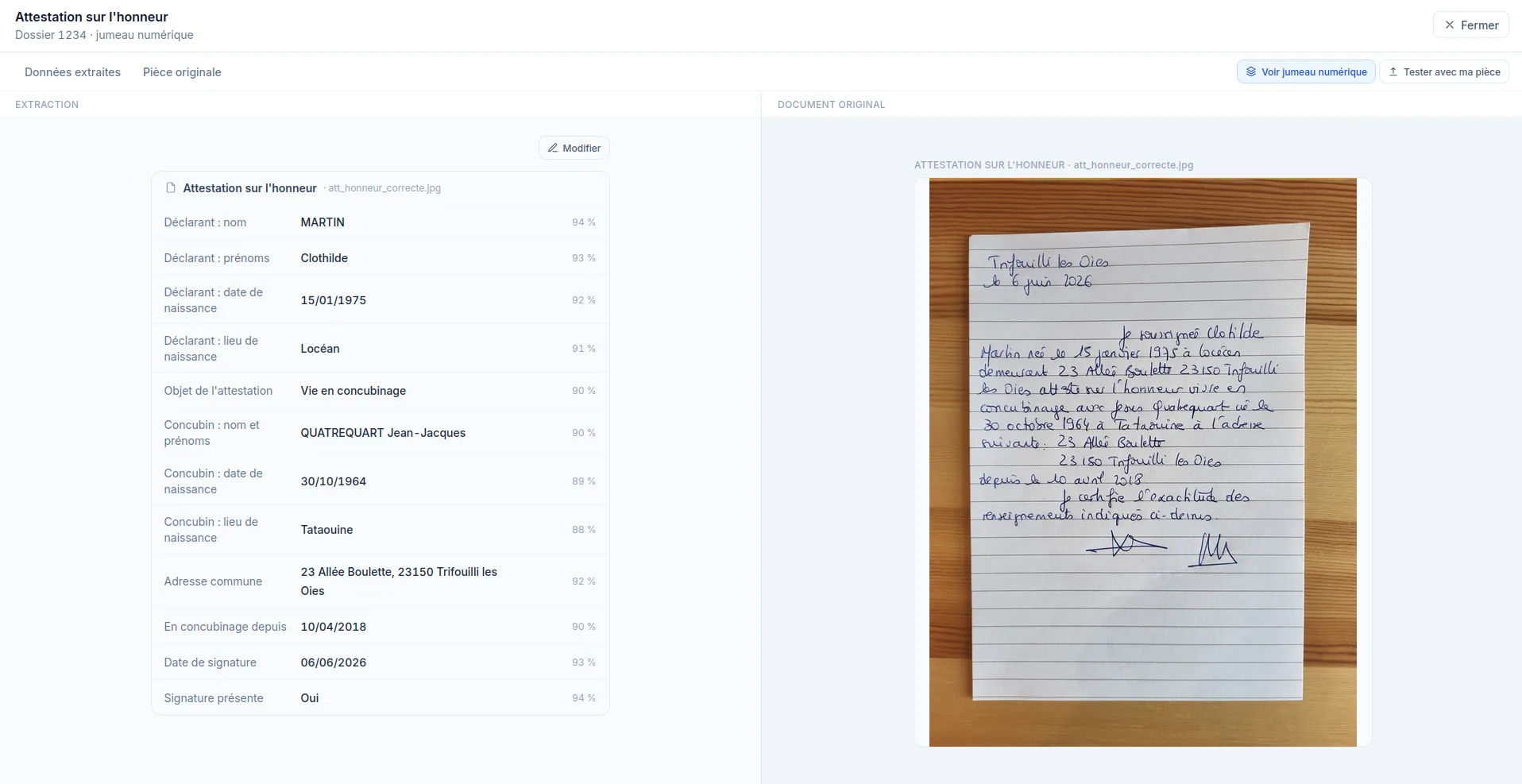
Les documents entrants sont transmis à la solution selon le canal défini avec le client.
ÉVIDENCE identifie le type de pièce, repère les informations utiles et extrait les données pertinentes.
Les informations détectées sont organisées dans un format exploitable par les traitements métier.
La solution assure les contrôles de cohérence, de complétude et de conformité attendus.
Les données structurées sont mises à disposition pour alimenter les workflows, applications ou chaînes de traitement existantes.
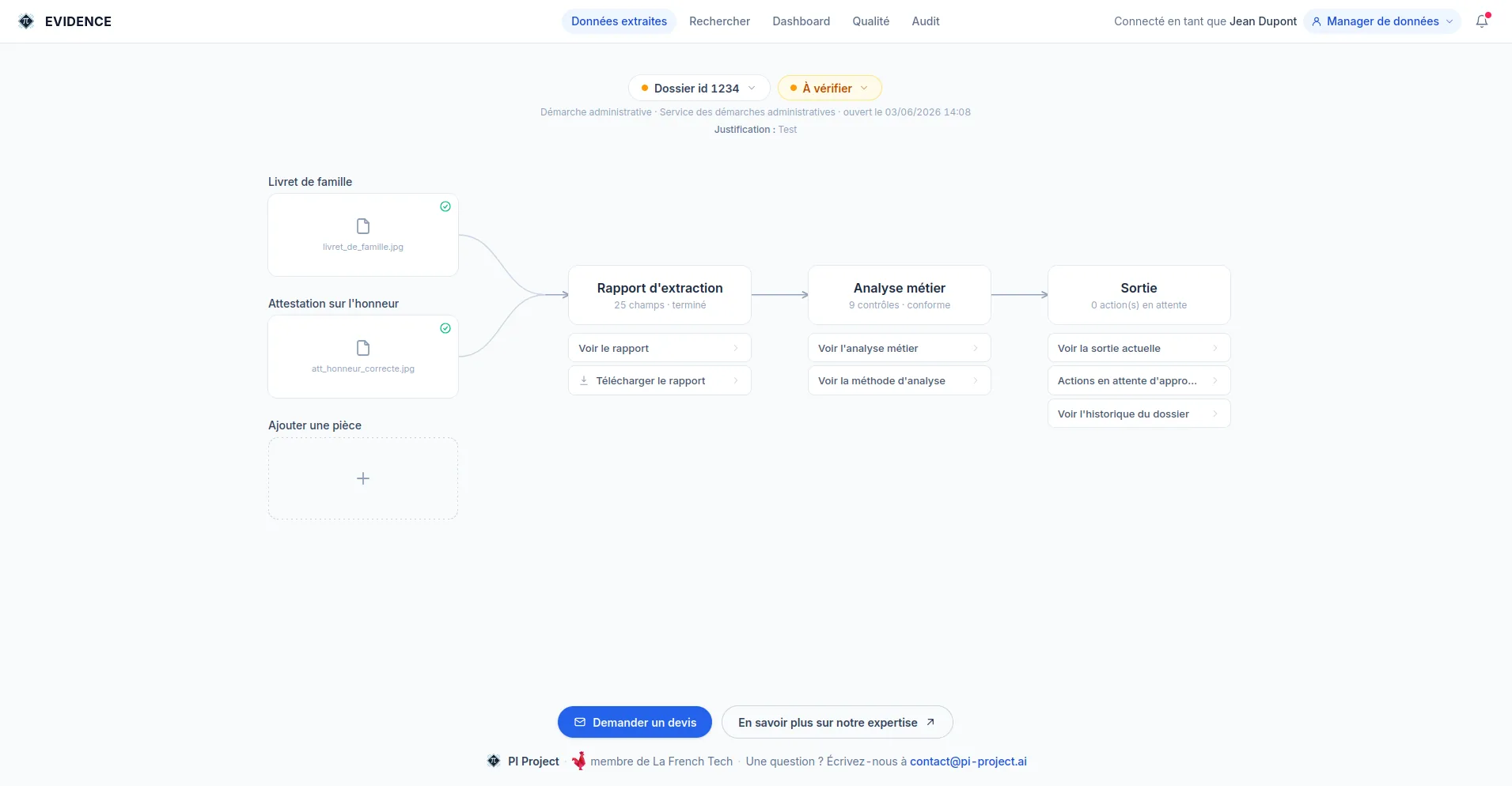
Un moteur de lecture automatique restitue le contenu d'un document. Il ne dit pas s'il l'a lu correctement. Or, dans un traitement administratif, le risque ne vient pas de la lecture : il vient de la décision prise à partir d'une donnée fausse, sans que personne ne s'en aperçoive.
Cette exigence n'est pas un raffinement : elle est inhérente à la technologie. Les moteurs de lecture de nouvelle génération (OCR, modèles de vision et de langage) sont des modèles probabilistes : ils estiment la lecture la plus vraisemblable, ils ne la certifient pas. Aussi performant soit-il, un tel modèle peut, ponctuellement, se tromper avec assurance. La garantie ne peut donc pas venir du modèle lui-même : elle doit se construire autour de lui.
ÉVIDENCE est la couche qui sépare une donnée simplement lue d'une donnée sur laquelle on peut agir. La valeur n'est pas d'extraire davantage : c'est de garantir ce qui est extrait.
Ce qui fait la différence entre une lecture et une donnée fiable :
Quand l'extraction échoue ou reste incertaine, ÉVIDENCE le déclare (lecture en échec, champ à confirmer) plutôt que de présenter une supposition comme un fait. Ce qui n'a pas été lu de façon fiable est signalé, jamais maquillé en donnée sûre.
Le système reconnaît quand il n'est pas sûr et rend la main à un agent à ce moment précis : aucune décision n'est prise automatiquement sur une donnée douteuse.
Chaque donnée reste rattachée à la pièce d'origine. Toute valeur peut être inspectée, vérifiée et corrigée à côté du document source : rien n'est produit sans preuve.
Chaque étape du traitement est enregistrée : la traçabilité est assurée de bout en bout. Une décision peut être expliquée et reconstituée dossier par dossier, ce qui garantit l'auditabilité et reste opposable en cas de contrôle ou de contestation.
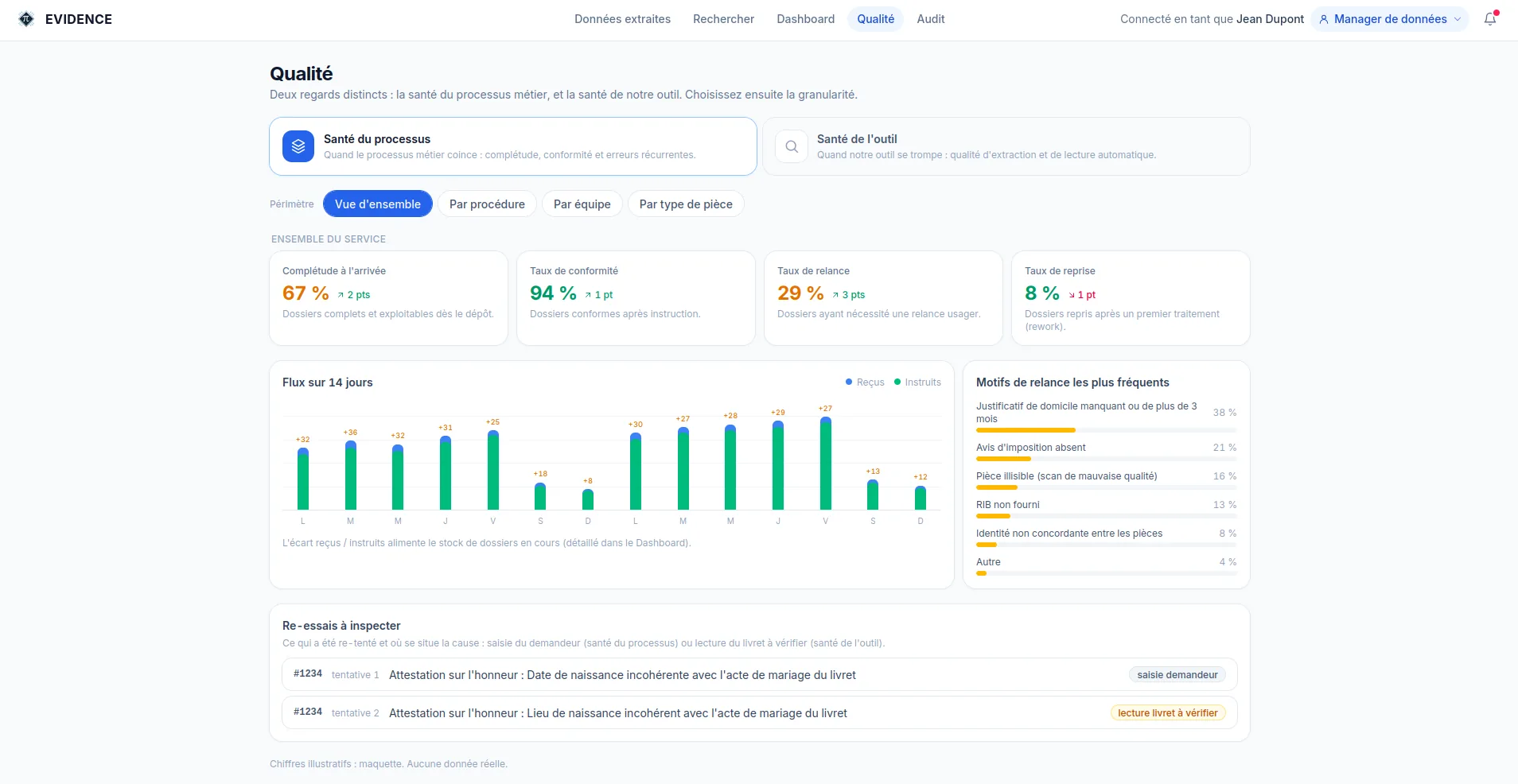
La fiabilité d'un traitement automatique ne se déclare pas, elle se mesure. ÉVIDENCE suit en continu la qualité des données produites, par type de pièce et dans le temps, et signale toute dérive avant qu'elle ne se propage.
Pour aller plus loin, la fiabilité obtenue peut être chiffrée : le niveau de fiabilité cesse d'être une intuition, il devient une valeur vérifiable, documentée et opposable.
La qualité est suivie par type de document et dans le temps. Une baisse de qualité est détectée, pas subie.
Un échantillon dimensionné est re-traité par une équipe humaine indépendante, pour un niveau de confiance défini à l'avance.
Les résultats sont chiffrés et documentés. Vous ne nous croyez pas sur parole : vous vérifiez.
C'est aussi tout l'objet d'une première étape de preuve : mesurer la fiabilité d'ÉVIDENCE sur vos propres documents, avec des indicateurs que vous pouvez contrôler, avant tout déploiement à grande échelle.
Derrière ces principes, il y a des méthodes établies, pas des affirmations. Voici, en clair, ce qu'elles permettent.
Pour garantir la fiabilité, il n'est pas nécessaire de re-vérifier tous les dossiers. La statistique permet de calculer le nombre exact de dossiers à contrôler pour atteindre un niveau de confiance donné. Point contre-intuitif : ce nombre dépend très peu du volume total.
Une approche naïve (« contrôler 10 % ») imposerait 1 000 puis 10 000 vérifications, pour une garantie qui, elle, n'est jamais chiffrée. Le dimensionnement, lui, fixe la garantie d'abord et en déduit l'effort minimal.
Population traitée
10 000
dossiers à contrôler
567
Population traitée
100 000
dossiers à contrôler
597
Multiplier le volume par 10 n'augmente presque pas l'effort de contrôle. Confiance 95 %, marge ± 4 points.
n ≈ z²·p(1-p) / E²
n : dossiers à contrôler · z : niveau de confiance · p : taux attendu · E : marge acceptée. Corrigé pour une population finie.
Nous ne donnons jamais un chiffre seul. Un taux de conformité est toujours accompagné de l'intervalle dans lequel se situe la valeur réelle. Sans cette marge, un pourcentage n'est qu'une affirmation.
La qualité est replacée sur une carte de contrôle. Un point qui franchit les limites déclenche une alerte et une inspection, avant que l'écart ne se diffuse dans les traitements.
Point signalé : dérive détectée et mise en revue.
Aucun système ne suffit seul. Les écarts potentiels traversent plusieurs filtres successifs : à chaque étage, une part est arrêtée. Ce qui subsiste en sortie est faible, connu et mesuré. C'est cette accumulation de contrôles, et non un modèle unique, qui produit la fiabilité.
En sortie, un dernier étage indépendant : le contrôle par échantillon dimensionné, qui transforme ce qui subsiste en une garantie chiffrée.
Méthodes mobilisées, à leur juste place :
Plusieurs familles de méthodes statistiques travaillent ensemble, chacune à sa juste place : aucune ne suffit seule, et c'est leur combinaison qui rend le résultat solide.
Un chiffre global rassure mais ne guide pas. ÉVIDENCE suit ses indicateurs à plusieurs niveaux de granularité (par type de pièce, par étape, par processus, par période), pour agir précisément là où l'écart se trouve.
La part des dossiers traités correctement du premier coup, sans reprise ni correction. C'est l'indicateur qui relie qualité et coût.
Global
94,2 %
Par type de pièce
Le même indicateur se décline par processus, par étape et par période. D'autres suivent la même logique : taux d'autonomie, taux de conformité final, taux de fausses alertes, pour une maîtrise explicite des faux positifs et des faux négatifs, chacun avec sa marge.
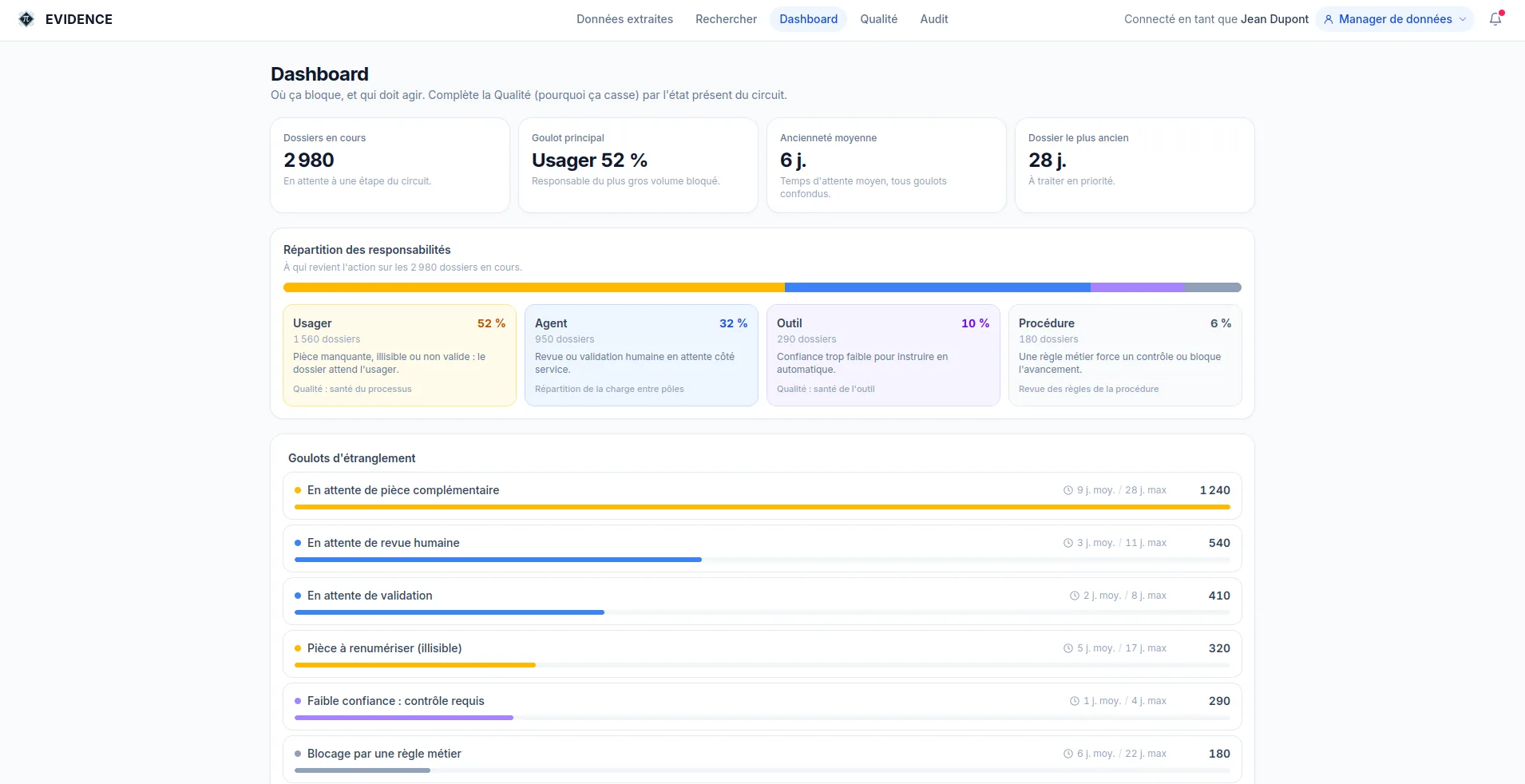
Chaque écart est rattaché à une cause. On traite ainsi l'origine du problème, pas seulement son symptôme, et l'on sait ce qui relève de l'outil ou du processus.
Répartition des causes d'écart
Distinguer ce qui vient de l'outil de ce qui vient du processus est décisif : les deux ne se corrigent pas au même endroit.
La performance d'un traitement dépend de deux choses distinctes : la qualité de l'outil (lecture, extraction, contrôles) et la qualité du processus métier (règles, pièces demandées, formulaires). ÉVIDENCE les mesure séparément.
On sait donc si un écart vient de l'outil ou du processus, et l'on peut améliorer chacun sans perturber l'autre. Deux boucles d'amélioration, un même socle de mesure.
Lecture, extraction, contrôles automatiques et seuils de décision. On la fait progresser sans toucher au métier.
Règles métier, pièces demandées, formulaires et circuits de décision. On la fait progresser sans dépendre d'un changement d'outil.
C'est ce découplage qui rend le progrès durable : la qualité s'améliore en continu des deux côtés, sans dépendance à un fournisseur ou à un modèle unique.
On imagine souvent ÉVIDENCE réservée aux grandes organisations déjà dotées d'un système d'information. C'est en effet l'un de ses usages : pour ces structures, la solution s'intègre aux applications et aux chaînes de traitement existantes.
Mais ÉVIDENCE fonctionne tout aussi bien à petite échelle. Une commune, un établissement ou un service qui ne dispose pas d'outil métier dédié peut l'utiliser sans rien déployer en interne, en s'appuyant sur un service public déjà existant pour collecter les pièces justificatives.
démarche.numerique.gouv.fr est un service de l'État, opéré par la DINUM, qui permet aux agents publics de créer des formulaires en ligne. Le principe est proche d'un formulaire grand public : les usagers déposent leur demande et leurs pièces justificatives de façon dématérialisée et structurée. Ce service joue le rôle de porte d'entrée, et ÉVIDENCE prend le relais pour transformer les pièces collectées en données exploitables.
Démarche en ligne
L'usager dépose ses justificatifs via un formulaire démarche.numerique.gouv.fr, sans envoi papier ni courriel à trier.
ÉVIDENCE
ÉVIDENCE lit les pièces reçues, vérifie les informations utiles et les transforme en données fiables et structurées.
Agent ou service
L'agent retrouve une donnée propre et vérifiée pour instruire le dossier, même sans logiciel métier dans la collectivité. ÉVIDENCE peut également agir : relancer l'usager par courriel pour obtenir une pièce corrigée ou complémentaire, ou transmettre les données extraites et structurées à un logiciel spécialisé.
Aucun développement, aucune infrastructure à installer : la collecte s'appuie sur un service public existant, ÉVIDENCE traite les pièces dans un cadre souverain et hébergé en France.
Découvrir démarche.numerique.gouv.frÉVIDENCE fournit un socle d'automatisation prêt à l'emploi, applicable bien au-delà des justificatifs présentés plus haut.
À partir de ce socle, PI Project conçoit ensuite une solution adaptée à votre environnement : vos documents, vos règles métier, vos contrôles, vos chaînes de traitement et vos contraintes d'intégration.
La solution peut être déclinée pour différents contextes :
Instruction de dossiers usagers
Contrôle de pièces administratives
Vérification de situations familiales ou de résidence
Traitement de justificatifs liés à l'hébergement ou à la vie commune
Structuration de documents entrants
Alimentation de workflows métier ou de systèmes existants
La souveraineté numérique est un enjeu déterminant pour les acteurs publics, en particulier lorsque les documents traités contiennent des données à caractère personnel.
Avec ÉVIDENCE, PI Project fait le choix d'une souveraineté concrète : les données sont hébergées en France, traitées dans un cadre juridique européen maîtrisé et aucun fournisseur situé en dehors de l'Union européenne n'intervient dans la chaîne de traitement.
Ce que cela signifie concrètement :
Données hébergées en France
Chaîne de traitement sans fournisseur situé hors Union européenne
Approche agnostique sur les modèles
Pas de dépendance à un fournisseur unique
Adaptation aux contraintes de chaque organisation
Maîtrise des finalités, des usages et des données par le client
ÉVIDENCE est également conçue dans une logique d'indépendance technologique. PI Project ne dépend pas d'un fournisseur unique, d'une technologie imposée ou d'un modèle propriétaire spécifique. Cette approche limite les risques de verrouillage technologique et permet d'adapter la solution aux exigences de chaque organisation.
PI Project intervient en qualité de sous-traitant RGPD : le client conserve la maîtrise de ses données, de ses finalités et de ses usages.
La performance économique d'un processus documentaire se joue souvent sur des tâches peu visibles mais fortement consommatrices de ressources : lecture des pièces, recherche des informations utiles, rapprochement, contrôle ou orientation des dossiers.
En automatisant l'extraction et la structuration des données issues des justificatifs, ÉVIDENCE permet de réduire le temps consacré à ces opérations répétitives mais essentielles.
La solution contribue ainsi à maîtriser le coût unitaire des dossiers traités, à absorber plus efficacement les pics d'activité et à réserver l'intervention humaine aux contrôles spécifiques, aux arbitrages et aux situations qui nécessitent réellement une expertise métier.
ÉVIDENCE s'adresse aux administrations publiques, collectivités territoriales, hôpitaux et plus largement tout opérateur public qui souhaite industrialiser le traitement de ses pièces justificatives sans perdre la maîtrise de ses données, de ses traitements et de ses dépendances technologiques.
La solution s'inscrit dans une logique de rigueur, de transparence, de traçabilité, de conformité et de confiance.
Administrations publiques
Établissements publics
Collectivités territoriales
Hôpitaux
Opérateurs publics
ÉVIDENCE est une solution souveraine, hébergée en France et conçue pour la sphère publique. À ce titre, les collectivités territoriales peuvent, selon leur éligibilité, mobiliser des dispositifs d'accompagnement dédiés à l'adoption d'une IA souveraine.
La Banque des Territoires (groupe Caisse des Dépôts) a lancé le programme Territoires d'IA, qui prévoit notamment un guichet de cofinancement destiné à faciliter l'acquisition de solutions d'IA souveraine par les collectivités.
Les conditions d'éligibilité, le montant et la nature du financement relèvent de la Banque des Territoires et sont appréciés au cas par cas. PI Project n'intervient pas dans l'instruction de ces demandes.
Découvrir le programme Territoires d'IAÉchanger avec PI Project
Présentez-nous vos documents et vos cas d'usage : nous étudions leur automatisation avec ÉVIDENCE et vous adressons une proposition adaptée.