PartRef Rodeo
Accès opérateur à des catalogues fragmentés, à travers plusieurs générations du produit
R2C dispose d'une documentation historique couvrant plusieurs variantes de Rodéo. Ces documents existent, mais sous forme de scans : ils ne sont pas directement interrogeables et ne permettent pas une recherche simple dans le texte.
La difficulté ne se limite pas à cette absence de recherche plein texte. Au sein d'un même document, plusieurs formes de références peuvent coexister. Certaines pièces apparaissent dans plusieurs variantes, parfois à plusieurs endroits, avec des conventions de nommage susceptibles de varier selon les générations, les sections ou le contexte technique. Dans ces conditions, exploiter la documentation devient difficile dès que l'utilisateur ne dispose que d'une pièce, d'une référence partielle ou d'un indice isolé : il faut savoir où chercher, dans quelle variante, sous quelle forme la pièce peut être désignée, et comment interpréter les différentes occurrences trouvées.
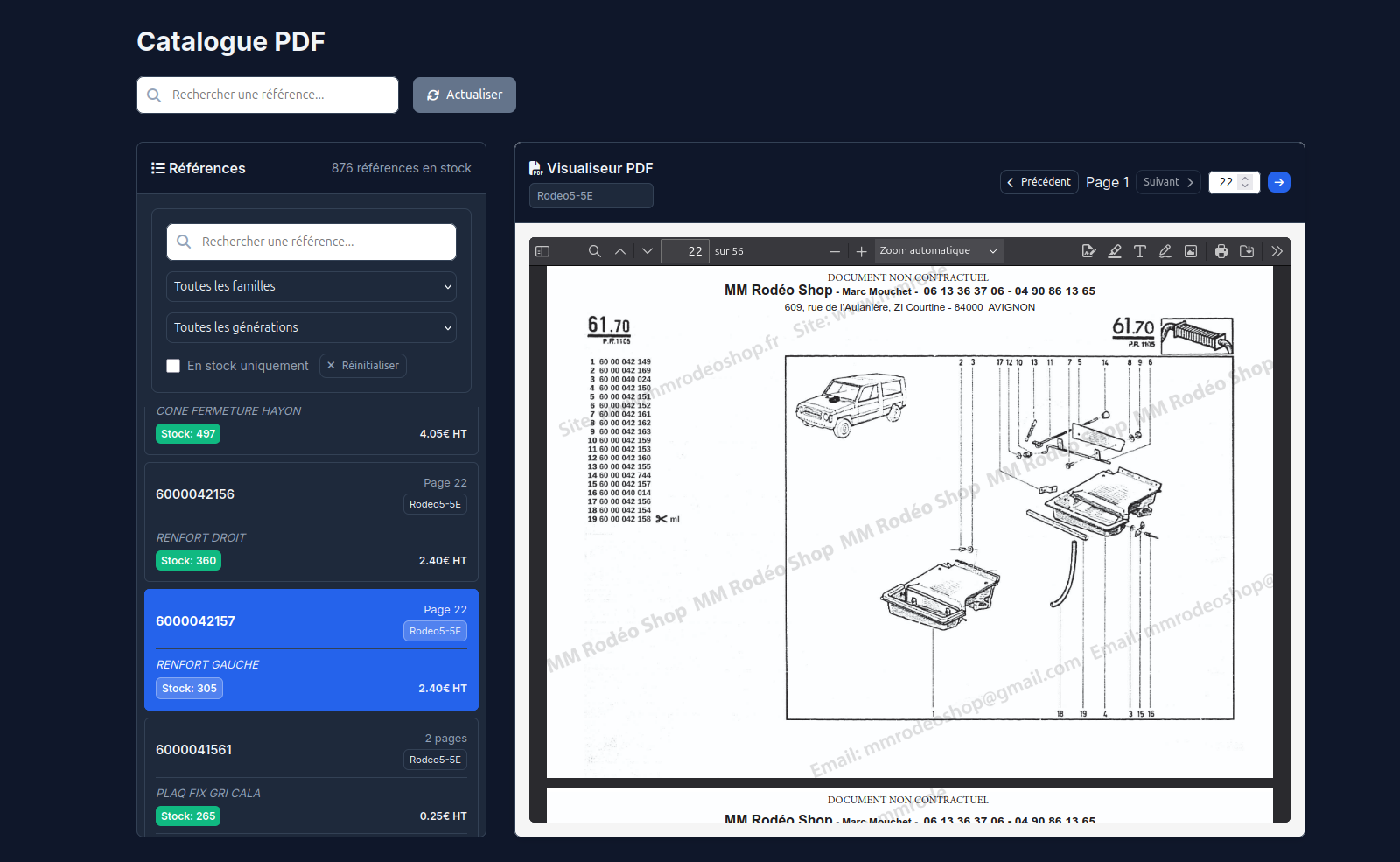
PartRef Rodeo transforme cette documentation historique en point d'accès exploitable. Le système rend les scans interrogeables, organise les résultats par document, page et variante, puis restitue chaque occurrence dans son contexte visuel. Il ne s'agit donc pas seulement d'extraire du texte, mais de conserver le lien entre chaque information et sa source : document, variante, page, zone visuelle et environnement documentaire.
Cette traçabilité permet de combiner recherche exacte, recherche approchée et vérification opérateur, sans produire une simple liste de correspondances ambiguës. La documentation reste la source de vérité centrale : la solution en change simplement le mode d'accès, en affichant directement la page concernée pour permettre à l'utilisateur de vérifier, contextualiser et lever les doutes éventuels.
Croisement avec les données métier
Une fois les références extraites et contextualisées, PartRef Rodeo ne se limite pas à la navigation documentaire. Les occurrences identifiées peuvent être rapprochées des données de stock du client : références présentes en stock, unités déclarées, soldes, formats de codes, pièces orphelines ou incohérences entre catalogue et données opérationnelles.
Ce croisement fait émerger des anomalies qui resteraient difficiles à détecter dans une lecture documentaire classique : unités incohérentes, soldes négatifs, références mal formées, pièces présentes en stock mais difficiles à rattacher à une documentation, ou références documentées mais absentes des données opérationnelles.
La valeur du système ne tient donc pas seulement à la recherche dans les catalogues scannés. Elle tient au lien établi entre patrimoine documentaire et référentiel métier : la documentation devient un support de contrôle, de rapprochement et d'audit.
Effet opérationnel
L'utilisateur peut retrouver une pièce ou une référence sans connaître à l'avance le bon catalogue, la bonne page ou la bonne convention de nommage. L'outil réduit ainsi le coût d'usage d'une documentation ancienne et fragmentée, tout en révélant des incohérences dans les données opérationnelles associées.
Il ne remplace pas la connaissance métier : il la rend plus efficace. Il évite que l'expertise des opérateurs soit consommée par des recherches manuelles longues, ambiguës et dépendantes de la mémoire individuelle, et concentre l'intervention humaine sur les cas où une décision ou une correction est réellement nécessaire.
- Ingestion de documents scannés
- Extraction de contenu non interrogeable
- Indexation par document, page et variante
- Gestion de plusieurs patterns de références
- Recherche exacte et approchée
- Rapprochement avec les données de stock
- Détection d'anomalies métier
- Accès opérateur à la source documentaire